数据流水线#
总览#
如下图所示,数据流水线由两个部分组成:Dataset 和 DataPipeline。
Dataset:负责标准化用户数据集,即将它们转换为 Pointrix 的统一数据格式:这个数据格式包含三部分,相机先验,点云先验,以及观测信息。相机先验主要包含相机的内外参信息, 点云先验主要为离线SFM等方法得到的初始化点云信息。观测信息包含各种相机观察到的以及处理后信息,例如rgb,depth,normal等。Pointrix提供了常用的数据集提取代码,用户如需要 加载自定义的数据,则需要重载对应的
_load_camera_prior,_load_pointcloud_prior, 以及_load_metadata函数。DataPipeline:Pointrix 中的标准数据流提供了稳定的数据流给训练器。这个类的主要函数是
next_train()和next_val(),这两个函数可以返回Batch。这个batch将用于渲染和损失计算。同时DataPipeline 也将给模型提供相机的初始化以及点云的初始化,如下图所示:
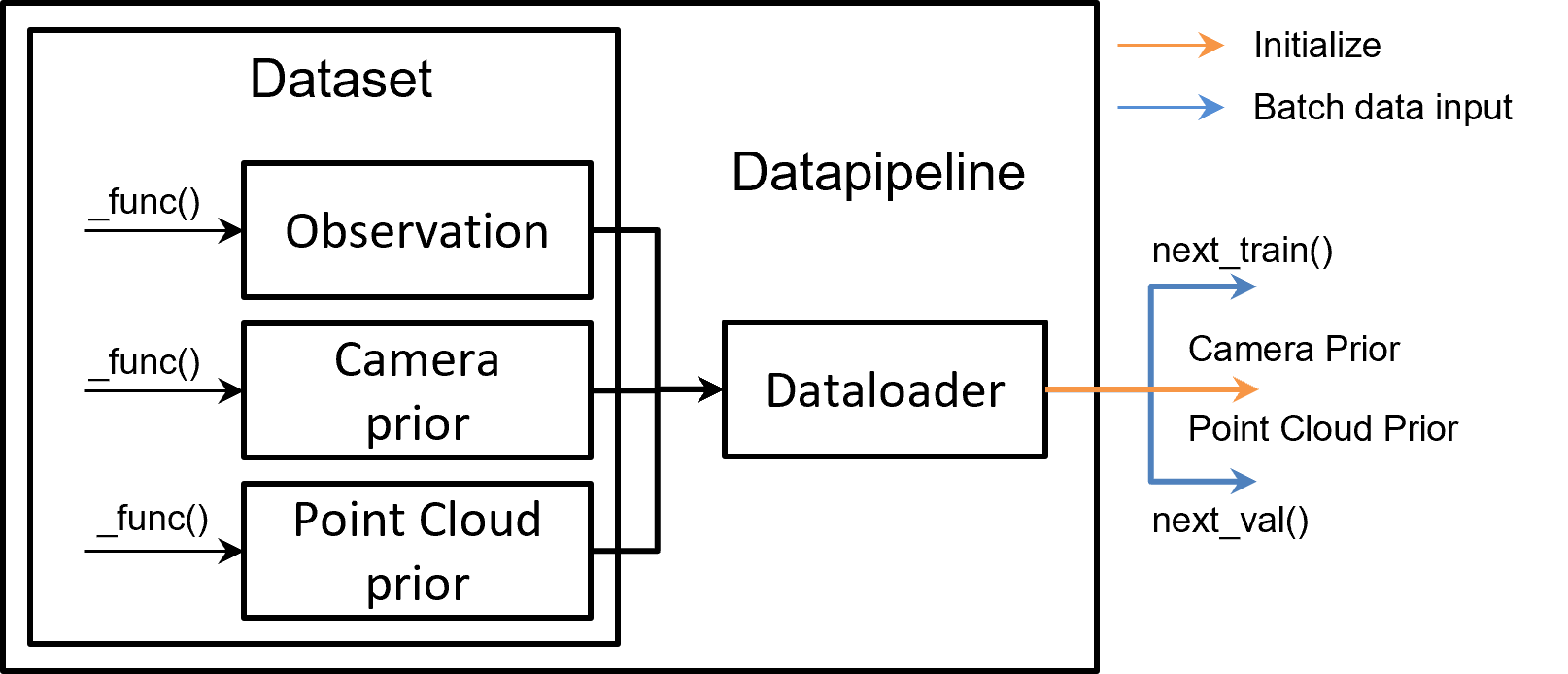
Dataset#
Dataset 中定义了三种基本数据类型,包括观测,相机先验,和点云先验。
观测:即为相机的观测,默认包含RGB图片,常见的观测包括RGB图片,深度图,表面法向等信息。这些观测通常作为模型的监督。
相机先验:主要包含相机的内外参等相机模型的先验信息,通常作为模型测相机的先验,如果相机先验足够准确 (例如通过Colmap获得的相机位姿),用户可以选择不优化相机模型,直接采用相机先验中的内外参作为渲染的输入。
点云先验:通过随机/Dust3R/Colmap 获得的点云先验,作为点云模型的初始化。
Note
如果需要载入用户自定义的数据集,用户需要重载修改对应的观测,相机先验,以及 点云先验对应的函数。 相关例子可以看教程中的为点云添加监督。
DataPipeline#
在数据集部分定义好了观测,相机先验以及点云先验的载入函数后,DataPipeline 会自动处理,通过next_train() 和 next_val()
函数来为训练过程提供数据流,同时会为模型测提供点云先验以及相机先验。用户通常不需要关心这部分的细节。
相关配置#
trainer:
datapipeline:
data_set: "ColmapDataset"
shuffle: True
batch_size: 1
num_workers: 0
dataset:
data_path: "/home/linzhuo/gj/data/garden"
cached_observed_data: True
scale: 0.25
white_bg: False
observed_data_dirs_dict: {"image":"images"}
data_path: 数据集的路径
data_set: 数据集的类型,由注册器索引。
shuffle: 是否随机打乱数据
batch_size: 批处理大小
num_workers: dataloader 中的num_workers
dataset
cached_metadata: 是否引入缓存加载数据
scale: 图片尺度大小
white_bg: 是否白色背景
observed_data_dirs_dict:{key: value}, 其中key为观测的变量名,value为观测的路径。例如{“image”: “images”}, 表示为,观测变量名为image的路径为self.data_root/images.