Data Pipeline#
As shown in the diagram below, the data pipeline consists of two main components: Dataset and DataPipeline.
Dataset: Responsible for standardizing user datasets, converting them into Pointrix’s unified data format. This format includes three parts: camera priors, point cloud priors, and observation information. Camera priors primarily contain intrinsic and extrinsic parameters of the cameras. Point cloud priors consist of initial point cloud information obtained from methods like offline SFM. Observation information includes various processed data observed by cameras, such as RGB, depth, normals, etc. Pointrix provides commonly used dataset extraction code. Users needing to load custom data must override corresponding functions:
_load_camera_prior,_load_pointcloud_prior, and_load_metadata.DataPipeline: The standard data flow in Pointrix provides a stable stream of data to the trainer. The main functions of this class are
next_train()andnext_val(), which return batches used for rendering and loss calculation. DataPipeline also initializes cameras and point clouds for the model, as depicted in the diagram below:
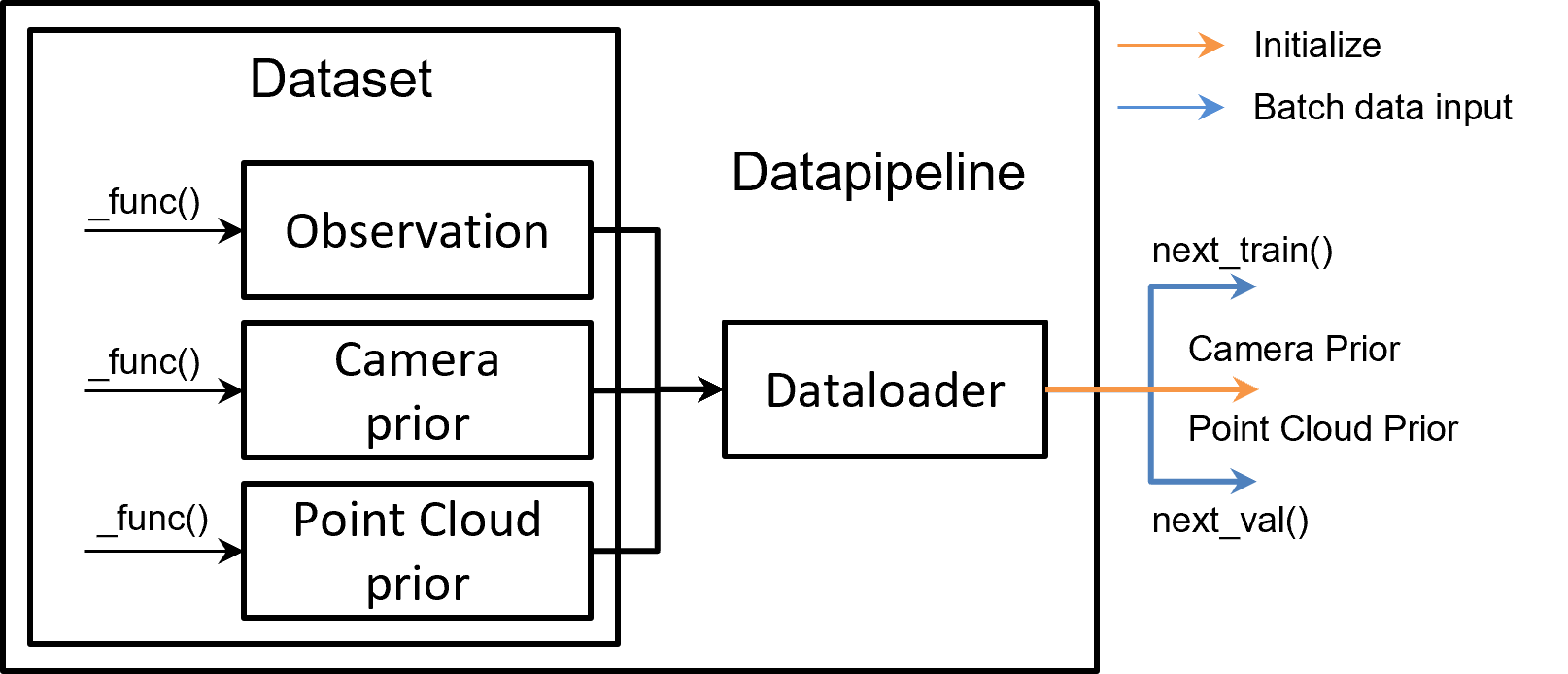
Dataset#
The Dataset defines three basic data types: Observation, Camera Priors, and Point Cloud Priors.
Observation: Refers to the data captured by the camera, typically including RGB images. Common observations include RGB images, depth maps, surface normals, etc. These observations are usually used as supervision for the model.
Camera Priors: Mainly include the intrinsic and extrinsic parameters of the camera, which are prior information about the camera model. They are typically used as priors for the camera in the model. If the camera priors are accurate enough (e.g., camera poses obtained via Colmap), users may choose not to optimize the camera model and directly use the intrinsic and extrinsic parameters from the camera priors as input for rendering.
Point Cloud Priors: Point cloud priors obtained through random sampling/Dust3R/Colmap, used as the initialization for the point cloud model.
Note
To load custom datasets, users must override functions corresponding to observation, camera priors, and point cloud priors. For relevant examples, refer to the tutorial on Adding Supervision to Point Clouds.
DataPipeline#
Once the functions for loading Observations, Camera Priors, and Point Cloud Priors are defined in the dataset section, the DataPipeline will automatically handle the data flow through the next_train() and next_val() functions to provide data streams for the training process. It will also supply Point Cloud Priors and Camera Priors for model testing. Users generally do not need to concern themselves with these details.